Chapter 4 ANOVA
4.1 One-Way Independent ANOVA
An example from Hays (1974, pp. 476-478):
“An experiment was carried out to study the effect of a small lesion introduced into a particular structure in a rat’s brain on his ability to perform in a discrimination problem. The particular structure studied is bilaterally symmetric. so that the lesion could be introduced into the structure on the right side of the brain, the left side, both sides, or neither side (a control group). Four groups of randomly selected rats were formed, and given the various treatments.[…] After a period of postoperative recovery, each rats was given the same series of discrimination problems. The dependent variable score was the average number of trials it took each rat to learn the task to some criterion level. The null hypothesis was that the four treatment populations of rats are identical in their average ability to learn this task:
H0: \(\mu\)1 = \(\mu\)2 = \(\mu\)3 = \(\mu\)4
as against the hypothesis that treatment differences exist:
H1: not H0.
The alpha level chosen for the experiment was .05.”
| Score | Group |
|---|---|
| 20 | 1 |
| 18 | 1 |
| 26 | 1 |
| 19 | 1 |
| 26 | 1 |
| 24 | 1 |
| 26 | 1 |
| 24 | 2 |
| 22 | 2 |
| 25 | 2 |
| 25 | 2 |
| 20 | 2 |
| 21 | 2 |
| 34 | 2 |
| 18 | 2 |
| 32 | 2 |
| 23 | 2 |
| 22 | 2 |
| 20 | 3 |
| 22 | 3 |
| 30 | 3 |
| 27 | 3 |
| 22 | 3 |
| 24 | 3 |
| 28 | 3 |
| 21 | 3 |
| 23 | 3 |
| 25 | 3 |
| 18 | 3 |
| 30 | 3 |
| 32 | 3 |
| 27 | 4 |
| 35 | 4 |
| 18 | 4 |
| 24 | 4 |
| 28 | 4 |
| 32 | 4 |
| 16 | 4 |
| 18 | 4 |
| 25 | 4 |
4.1.1 Results Overview
| By Hand | JASP | SPSS | SAS | Minitab | R | |
|---|---|---|---|---|---|---|
| F | 0.307377 | 0.3082 | 0.308 | 0.31 | 0.31 | 0.308 |
4.1.2 By Hand
Calculations by hand can be found in Hays, 1974, pp. 476-478.
Results:
| Source | SS | df | MS | F |
|---|---|---|---|---|
| Treatments (between groups) | 22.6 | 3 | 7.5 | 0.307377 |
| Error (within groups) | 878.9 | 36 | 24.4 | NA |
| Totals | 901.5 | 39 | NA | NA |
Conclusion: The null hypothesis cannot be rejected, because the critical F value was 2.84.
Note: Hays reported F =\(\frac{7.5}{24.4}\). For a better comparison we transformed it to a decimal number.
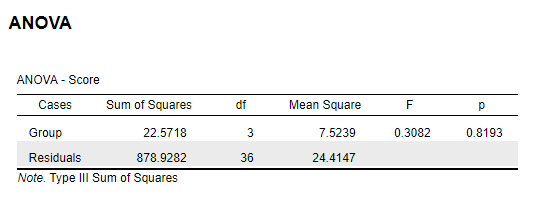
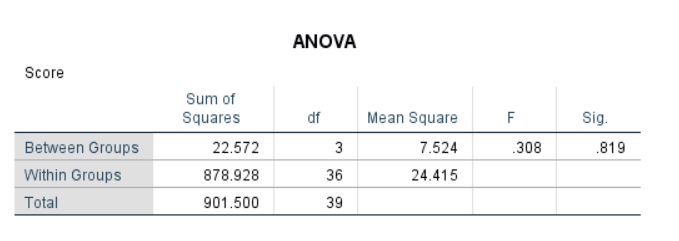
4.1.5 SAS
proc ANOVA data=anova;
title One-way ANOVA;
class Group;
model Score = Group;
means Group /hovtest welch;
run;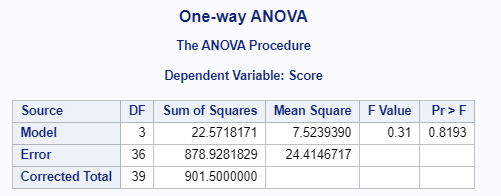
Figure 4.3: SAS Output for One-Way Independent ANOVA

4.1.7 R
## Compute the analysis of variance
results.anova <- aov(anova.data$Score ~ anova.data$Group, data = anova.data)
## Summary of the analysis
summary(results.anova)## Df Sum Sq Mean Sq F value Pr(>F)
## anova.data$Group 3 22.6 7.524 0.308 0.819
## Residuals 36 878.9 24.4154.2 Factorial Independent ANOVA
An example from Hays (1974, pp. 491-493, 508-512):
“Just as before, the experimental game is under the control of the experimenter, so that each subject actually obtains the same score. After a fixed number of trials, during which the subject gets the preassigned score, he is asked to predict what his score will be on the next group of trials. Before he predicts, the subject is given ‘information’ about how this score compares with some norm group. In one experimental condition he is told that his performance is above average for the norm group, in the second condition he is told that his score is average, and in the third condition he is told that his score is below average for the norm group. Once again, there are three experimental treatments in terms of ‘standings’: ‘above average’, ‘average’, ‘below average’. […]One half of the subjects are told that they are being compared with college men, and the other half are told that they are being compared with professional athletes. Hence, there are two additional experimental treatments: ‘college norms’, and ‘professional athlete norms’.
We wish to examine three null hypotheses:
there is no effect of the standing given the subject[…]
the actual norm group given the subjects has no effect […]
the norm-group-standing combination has no unique effect […]
The \(\alpha\) level chosen for each of these three tests will be .05.”
| Norms | Above | Average | Below |
|---|---|---|---|
| College men | 52 | 28 | 15 |
| College men | 48 | 35 | 14 |
| College men | 43 | 34 | 23 |
| College men | 50 | 32 | 21 |
| College men | 43 | 34 | 14 |
| College men | 44 | 27 | 20 |
| College men | 46 | 31 | 21 |
| College men | 46 | 27 | 16 |
| College men | 43 | 29 | 20 |
| College men | 49 | 25 | 14 |
| Professional Athlete | 38 | 43 | 23 |
| Professional Athlete | 42 | 34 | 25 |
| Professional Athlete | 42 | 33 | 18 |
| Professional Athlete | 35 | 42 | 26 |
| Professional Athlete | 33 | 41 | 18 |
| Professional Athlete | 38 | 37 | 26 |
| Professional Athlete | 39 | 37 | 20 |
| Professional Athlete | 34 | 40 | 19 |
| Professional Athlete | 33 | 36 | 22 |
| Professional Athlete | 34 | 35 | 17 |
N = 60
4.2.1 Results Overview
| By Hand | JASP | SPSS | SAS | Minitab | R | |
|---|---|---|---|---|---|---|
| F (Norm groups) | 0.35 | 0.3582 | 0.358 | 0.36 | 0.36 | 0.358 |
| F (Standings) | 209.80 | 209.6418 | 209.642 | 209.64 | 209.64 | 209.642 |
| F (Interaction) | 34.00 | 34.0075 | 34.007 | 34.01 | 34.01 | 34.007 |
4.2.2 By Hand
Calculations by hand can be found in Hays, 1974, pp. 508-512.
Results:
| Source | SS | df | MS | F |
|---|---|---|---|---|
| Rows (norm groups) | 4.2 | 1 | 4.20 | 0.35 |
| Columns (standings) | 4994.1 | 2 | 2497.05 | 209.80 |
| Interaction | 810.2 | 2 | 405.10 | 34.00 |
| Error (within cells) | 643.2 | 54 | 11.90 | NA |
Conclusion: The null hypothesis cannot be rejected, for the main effect of norm groups. It can be rejected for the main effect of standings and the interaction effect.
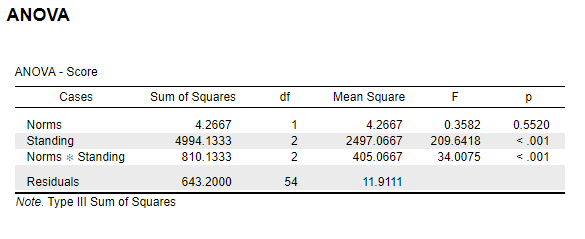
4.2.4 SPSS
DATASET ACTIVATE DataSet1.
UNIANOVA Score BY Norms Standing
/METHOD=SSTYPE(3)
/INTERCEPT=EXCLUDE
/CRITERIA=ALPHA(0.05)
/DESIGN=Norms Standing Norms*Standing.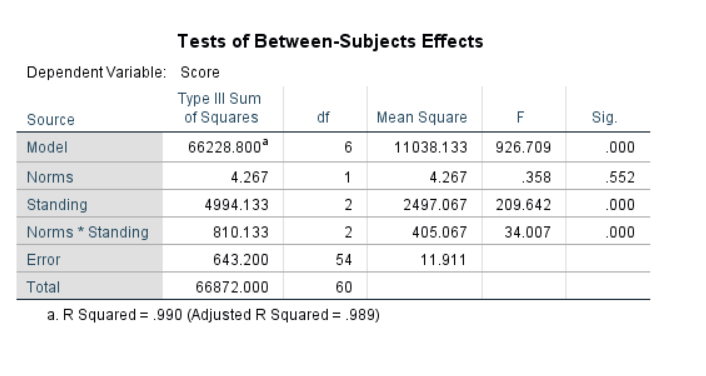
Figure 4.6: SPSS Output for Independent Factorial ANOVA
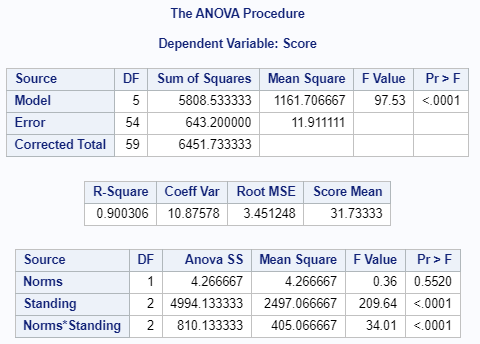
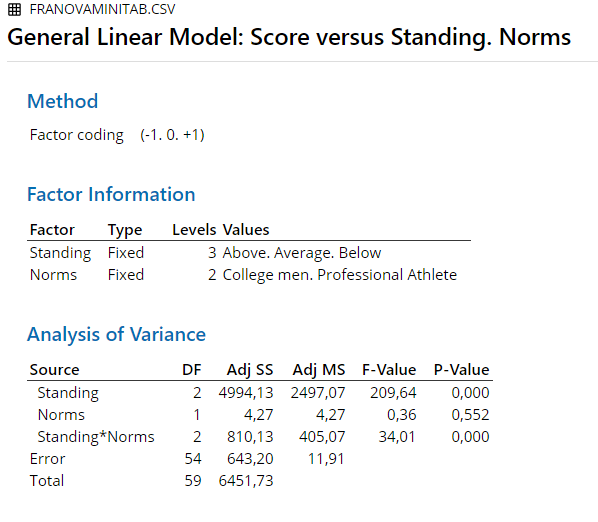
4.2.7 R
FIanova.data2 <- read.csv("Datasets/FIanova.csv", sep=",")
## Compute the analysis of variance
results.anova <- aov(FIanova.data2$Score ~ FIanova.data2$Standing * FIanova.data2$Norms, data = FIanova.data2)
## Summary of the analysis
summary(results.anova)## Df Sum Sq Mean Sq F value Pr(>F)
## FIanova.data2$Standing 2 4994 2497.1 209.642 < 2e-16
## FIanova.data2$Norms 1 4 4.3 0.358 0.552
## FIanova.data2$Standing:FIanova.data2$Norms 2 810 405.1 34.007 2.76e-10
## Residuals 54 643 11.9
##
## FIanova.data2$Standing ***
## FIanova.data2$Norms
## FIanova.data2$Standing:FIanova.data2$Norms ***
## Residuals
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 14.3 Kruskal-Wallis ANOVA
An example from Hays (1974, pp. 782-784):
“For example, suppose that three groups of small children were given the task of learning to discriminate between pairs of stimuli. Each child was given a series of pairs of stimuli, in which each pair differed in a variety of ways. However, attached to the choice of one member of a pair was a reward, and within an experimental condition, the cue for the rewarded stimulus was always the same. On the other hand, the experimental treatments themselves differed in the relevant cue for discrimination: in treatment I, the cue was form, in treatment II, color, and in treatment III, size. Some 36 children of the same sex and age were chosen at random and assigned at random to the three groups, with 12 children per group. The dependent variable was the number of trials to a fixed criterion of learning. Suppose that the data turned out the be as shown[…]”
| Treatment.I | Treatment.II | Treatment.III |
|---|---|---|
| 6 | 31 | 13 |
| 11 | 7 | 32 |
| 12 | 9 | 31 |
| 20 | 11 | 30 |
| 24 | 16 | 28 |
| 21 | 19 | 29 |
| 18 | 17 | 25 |
| 15 | 11 | 26 |
| 14 | 22 | 26 |
| 10 | 23 | 27 |
| 8 | 27 | 26 |
| 14 | 26 | 19 |
4.3.1 Results Overview
| By Hand | JASP | SPSS | SAS | Minitab | R | |
|---|---|---|---|---|---|---|
| H’ | 13.85 | 13.8444 | 13.844 | 13.8444 | 13.84 | 13.844 |
4.3.2 By Hand
Calculations by hand can be found in Hays, 1974, pp. 782-784.
Result:
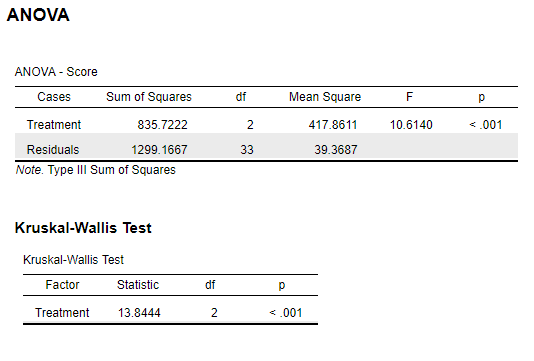
H = 13.85
Significant for \(\alpha\) = .01 or less.
4.3.4 SPSS
DATASET ACTIVATE DataSet1.
*Nonparametric Tests: Independent Samples.
NPTESTS
/INDEPENDENT TEST (Score) GROUP (Treatment) KRUSKAL_WALLIS(COMPARE=NONE)
/MISSING SCOPE=ANALYSIS USERMISSING=EXCLUDE
/CRITERIA ALPHA=0.05 CILEVEL=95.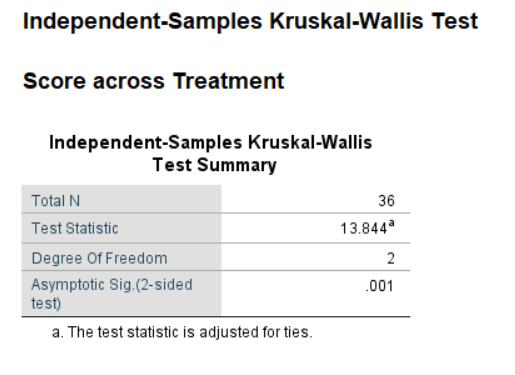
Figure 4.10: SPSS Output for Kruskal-Wallis ANOVA
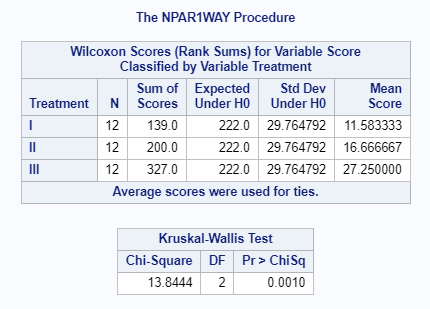
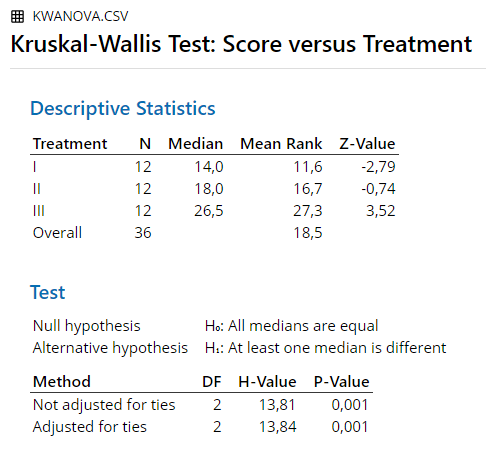
4.3.7 R
##
## Kruskal-Wallis rank sum test
##
## data: Score by Treatment
## Kruskal-Wallis chi-squared = 13.844, df = 2, p-value = 0.00098574.4 One-Way Repeated-Measures ANOVA
An example from Kerlinger (1969, pp. 242-248):
“A principal of a school and the members of his staff decided to introduce a program of education in intergroup relations as an addition to the school’s curriculum. One of the problems that arose was in the use of motion pictures. Films were shown in the initial phases of the program, but the results were not too encouraging. […} They decided to test the hypothesis that seeing the films and then discussing them would improve the viewers’ attitudes toward minority group members more than would just seeing the films. For a preliminary study the staff randomly selected a group of students from the total student body and attempted to pair the students on intelligence and socioeconomic background until ten pairs were obtained […] Each member of each pair was randomly assigned to either an experimental or a control group, and then both groups were shown a new film on intergroup relations. The A1 (experimental) group had a discission session after the picture was shown; the A2 (control) group had no such discussion afrer the film. Both groups were tested with a scale designed to measures attitudes toward minority groups.”
| A1.experimental. | A2.control. |
|---|---|
| 8 | 6 |
| 9 | 8 |
| 5 | 3 |
| 4 | 2 |
| 2 | 1 |
| 10 | 7 |
| 3 | 1 |
| 12 | 7 |
| 6 | 6 |
| 11 | 9 |
4.4.1 Results Overview
| By Hand | JASP | SPSS | SAS | Minitab | R | |
|---|---|---|---|---|---|---|
| F | 22.47 | 22.5 | 22.5 | 22.5 | 22.5 | 22.5 |
4.4.2 By Hand
Calculations by hand can be found in Kerlinger, 1969, pp. 242-248.
Results:
| Source | df | SS | MS | F |
|---|---|---|---|---|
| Within groups | 1 | 20 | 20.00 | 22.47 |
| Between groups | 9 | 182 | 20.22 | 22.72 |
| Residual | 9 | 8 | 0.89 | NA |
| Totals | 19 | 210 | NA | NA |
Conclusion: All F-values are significant for \(\alpha\) = .001 or less.
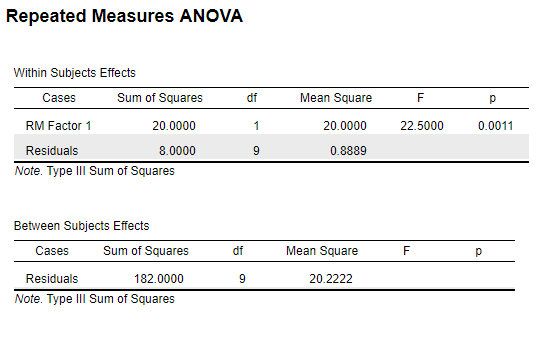
4.4.4 SPSS
DATASET ACTIVATE DataSet2.
GLM A1.experimental A2.control
/WSFACTOR=Condition 2 Polynomial
/METHOD=SSTYPE(3)
/CRITERIA=ALPHA(.05)
/WSDESIGN=Condition.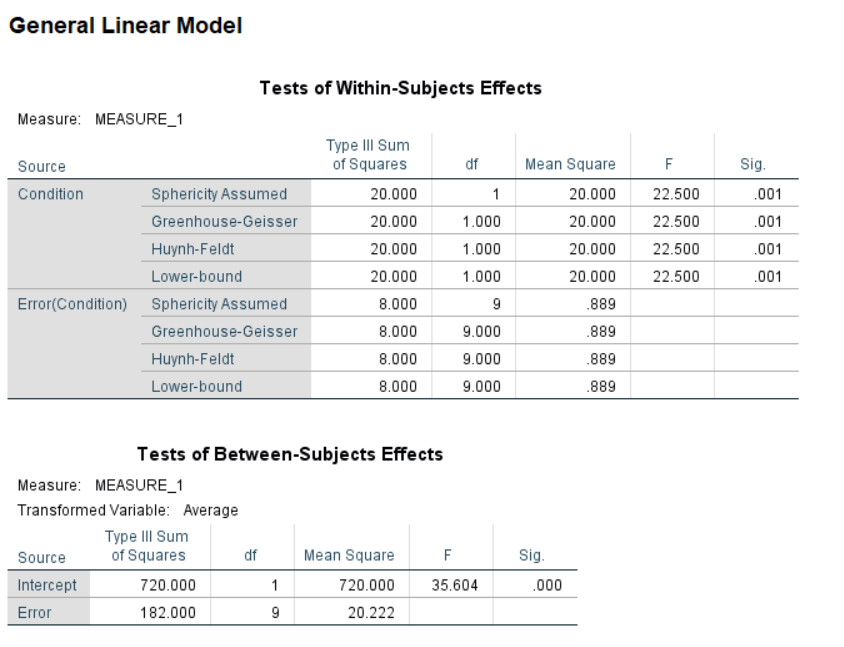
Figure 4.14: SPSS Output for One-Way Repeated-Measures ANOVA
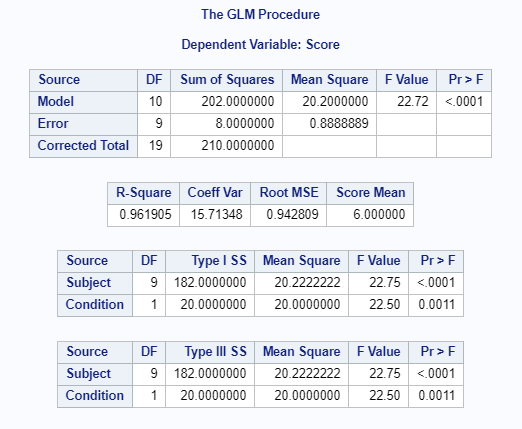
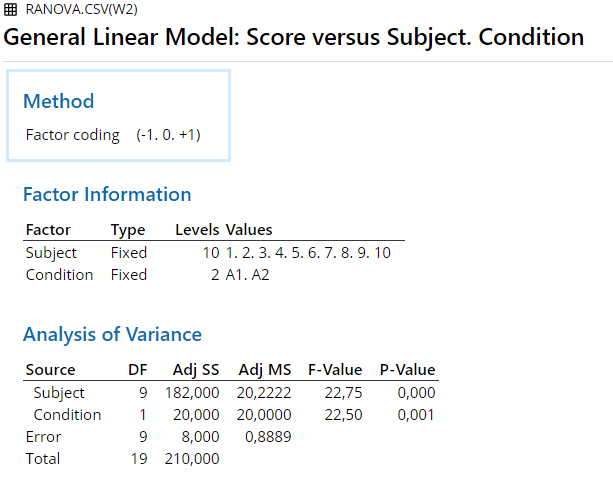
4.4.7 R
summary(aov(Score ~ as.factor(ranova.data2$Condition) + Error(as.factor(ranova.data2$Subject)/as.factor(ranova.data2$Condition)), data=ranova.data2))##
## Error: as.factor(ranova.data2$Subject)
## Df Sum Sq Mean Sq F value Pr(>F)
## Residuals 9 182 20.22
##
## Error: as.factor(ranova.data2$Subject):as.factor(ranova.data2$Condition)
## Df Sum Sq Mean Sq F value Pr(>F)
## as.factor(ranova.data2$Condition) 1 20 20.000 22.5 0.00105 **
## Residuals 9 8 0.889
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 14.5 Friedman Test
An example from Hays (1974, pp. 785-786):
“For example, in an experiment with four experimental treatments (J = 4), 11 groups of 4 matched subjects apiece were used. Within each matched group the four subjects were assigned at random to the four treatments, on subject per treatment.”
| Groups | Treatment.I | Treatment.II | Treatment.III | Treatment.IV |
|---|---|---|---|---|
| 1 | 1 | 4 | 8 | 0 |
| 2 | 2 | 3 | 13 | 1 |
| 3 | 10 | 0 | 11 | 3 |
| 4 | 12 | 11 | 13 | 10 |
| 5 | 1 | 3 | 10 | 0 |
| 6 | 10 | 3 | 11 | 9 |
| 7 | 4 | 12 | 10 | 11 |
| 8 | 10 | 4 | 5 | 3 |
| 9 | 10 | 4 | 9 | 3 |
| 10 | 14 | 4 | 7 | 2 |
| 11 | 3 | 2 | 4 | 13 |
4.5.1 Results Overview
| By Hand | JASP | SPSS | SAS | Minitab | R | |
|---|---|---|---|---|---|---|
| \(\chi^2\) | 11.79 | 11.9455 | 11.945 | NA | 11.95 | 11.945 |
4.5.2 By Hand
Calculations by hand can be found in Hays, 1974, pp. 785-786.
Result:
\(\chi^2\) = 11.79
Significant for \(\alpha\) = .01 or less.
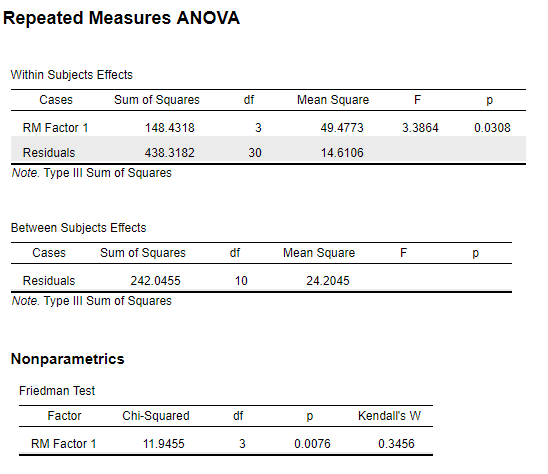
4.5.4 SPSS
DATASET ACTIVATE DataSet1.
*Nonparametric Tests: Related Samples.
NPTESTS
/RELATED TEST(Treatment.I Treatment.II Treatment.III Treatment.IV) FRIEDMAN(COMPARE=NONE)
/MISSING SCOPE=ANALYSIS USERMISSING=EXCLUDE
/CRITERIA ALPHA=0.05 CILEVEL=95.
Figure 4.18: SPSS Output for Friedman Test

4.5.7 R
friedman.test(Friedman.data2$Score, groups = Friedman.data2$Treatment, blocks = Friedman.data2$Groups)##
## Friedman rank sum test
##
## data: Friedman.data2$Score, Friedman.data2$Treatment and Friedman.data2$Groups
## Friedman chi-squared = 11.945, df = 3, p-value = 0.0075724.6 ANCOVA
An example from Field (2018 pp. 522-523, 576-577):
“Imagine we wanted to contribute to this literature by running a study in which we randomized people into three groups: (1) a control group […]; (2) 15 minutes of puppy therapy (a low-dose group); and (3) 30 minutes of puppy contact (a high-dose group). The dependent variable was a measure of happiness ranging from 0 (as unhappy as I can possibly imagine being) to 10 (as happy as I can possibly imagine being). […] The researchers […] suddenly realized that a participant’s love of dogs would affect whether puppy therapy would affect happiness. Therefore, they repeated the study on different participants, but included a self-report measure of love of puppies from 0 […] to 7.”
| Person | Dose | Happiness | Puppy_love |
|---|---|---|---|
| 1 | 1 | 3 | 4 |
| 2 | 1 | 2 | 1 |
| 3 | 1 | 5 | 5 |
| 4 | 1 | 2 | 1 |
| 5 | 1 | 2 | 2 |
| 6 | 1 | 2 | 2 |
| 7 | 1 | 7 | 7 |
| 8 | 1 | 2 | 4 |
| 9 | 1 | 4 | 5 |
| 10 | 2 | 7 | 5 |
| 11 | 2 | 5 | 3 |
| 12 | 2 | 3 | 1 |
| 13 | 2 | 4 | 2 |
| 14 | 2 | 4 | 2 |
| 15 | 2 | 7 | 6 |
| 16 | 2 | 5 | 4 |
| 17 | 2 | 4 | 2 |
| 18 | 3 | 9 | 1 |
| 19 | 3 | 2 | 3 |
| 20 | 3 | 6 | 5 |
4.6.1 Results Overview
| JASP | SPSS | SAS | Minitab | R | |
|---|---|---|---|---|---|
| F (Dose) | 4.1419 | 4.142 | 4.14 | 4.14 | 4.1419 |
| F (Puppy_love) | 4.9587 | 4.959 | 4.96 | 4.96 | 4.9587 |
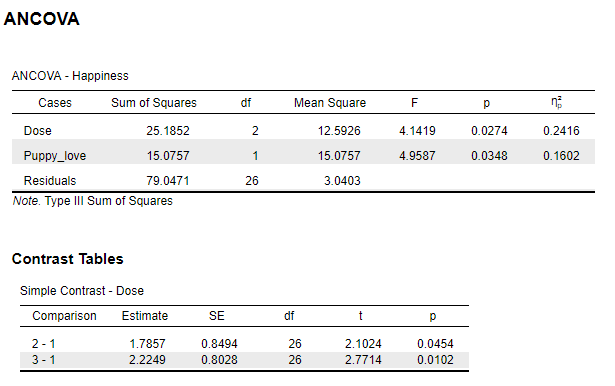
4.6.3 SPSS
UNIANOVA Happiness BY Dose WITH Puppy_love
/CONTRAST(Dose)=Simple
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/PRINT ETASQ
/CRITERIA=ALPHA(.05)
/DESIGN=Puppy_love Dose.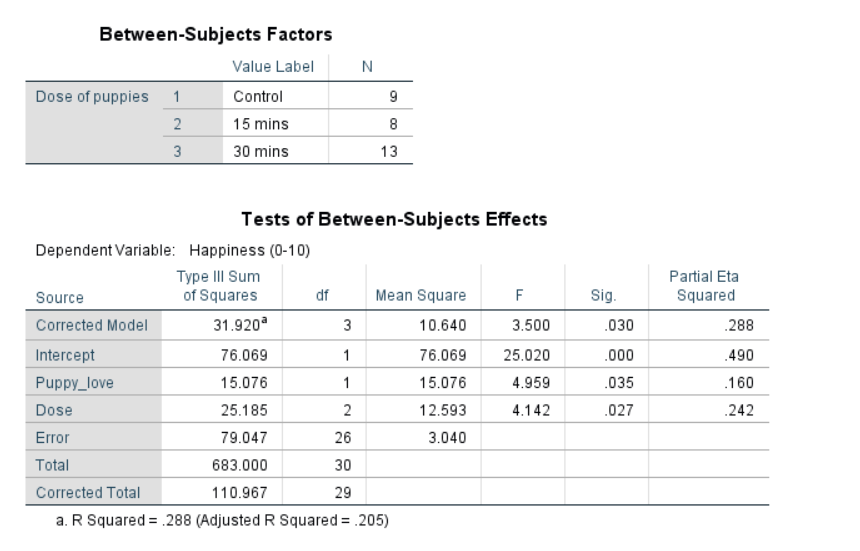
Figure 4.21: SPSS Output for ANCOVA
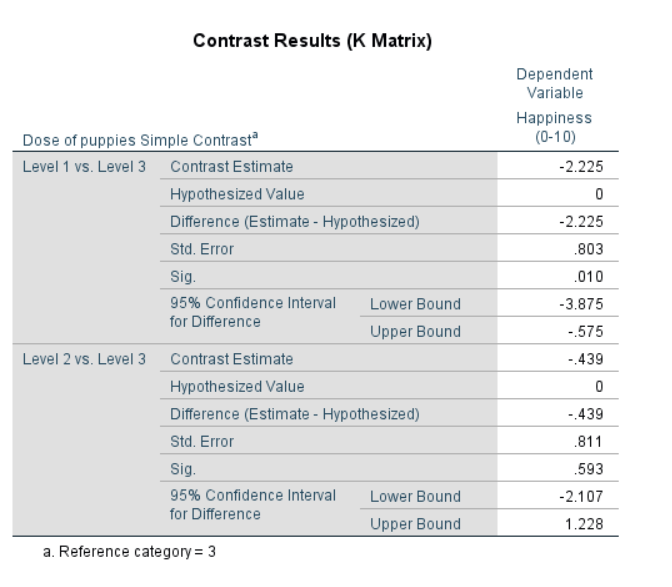
Figure 4.22: SPSS Output for ANCOVA Contrasts
4.6.4 SAS
PROC GLM data=work.ANCOVA;
CLASS Dose;
MODEL Happiness = Dose Puppy_love / SOLUTION ss3;
LSMEANS Dose / STDERR PDIFF CL ADJUST = BON;
OUTPUT OUT = pred p=ybar r=resid;
RUN;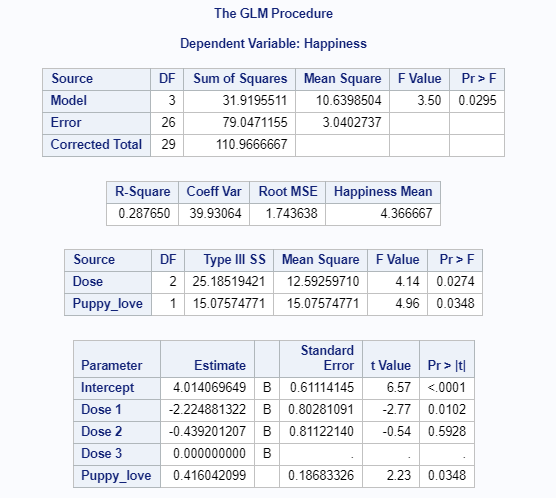
Figure 4.23: SAS Output for ANCOVA
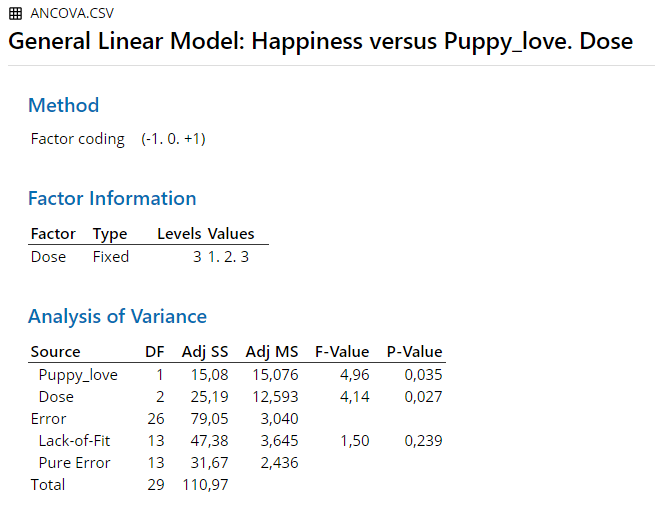
4.6.6 R
## Loading required package: carData## Anova Table (Type III tests)
##
## Response: Happiness
## Sum Sq Df F value Pr(>F)
## (Intercept) 12.943 1 4.2572 0.04920 *
## as.factor(Dose) 25.185 2 4.1419 0.02745 *
## Puppy_love 15.076 1 4.9587 0.03483 *
## Residuals 79.047 26
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 14.7 MANOVA
An example from Field (2018 pp. 738-739):
“Most psychopathologies have both behavioural and cognitive elements to them. For example, for someone with OCD who has an obsession with germs and contamination, the disorder might manifest itself in the number of times they both wash their hands (behavior) and think about washing their hands (cognition). To gauge the success of therapy, it is not enough to look only at behavioural outcomes (such as whether obsessive behaviours are reduced); we need to look at whether cognitions are changed too. Hence, the clinical psychologist measured two outcomes: the occurrence of obsession-related behaviours (Actions) and the occurrence of obsession-related cognitions (Thoughts) on a single day.”
| Group | Actions | Thoughts |
|---|---|---|
| 1 | 5 | 14 |
| 1 | 5 | 11 |
| 1 | 4 | 16 |
| 1 | 4 | 13 |
| 1 | 5 | 12 |
| 1 | 3 | 14 |
| 1 | 7 | 12 |
| 1 | 6 | 15 |
| 1 | 6 | 16 |
| 1 | 4 | 11 |
| 2 | 4 | 14 |
| 2 | 4 | 15 |
| 2 | 1 | 13 |
| 2 | 1 | 14 |
| 2 | 4 | 15 |
| 2 | 6 | 19 |
| 2 | 5 | 13 |
| 2 | 5 | 18 |
| 2 | 2 | 14 |
| 2 | 5 | 17 |
4.7.1 Results Overview
| JASP | SPSS | SAS | Minitab | R | |
|---|---|---|---|---|---|
| F (Multivariate Pillai) | 2.5567 | 2.557 | 2.56 | 2.557 | 2.5567 |
| F (Univariate Actions) | 2.7706 | 2.771 | 2.77 | 2.770 | 2.7706 |
| F (Univariate Thoughts) | 2.1541 | 2.154 | 2.15 | 2.150 | 2.1541 |
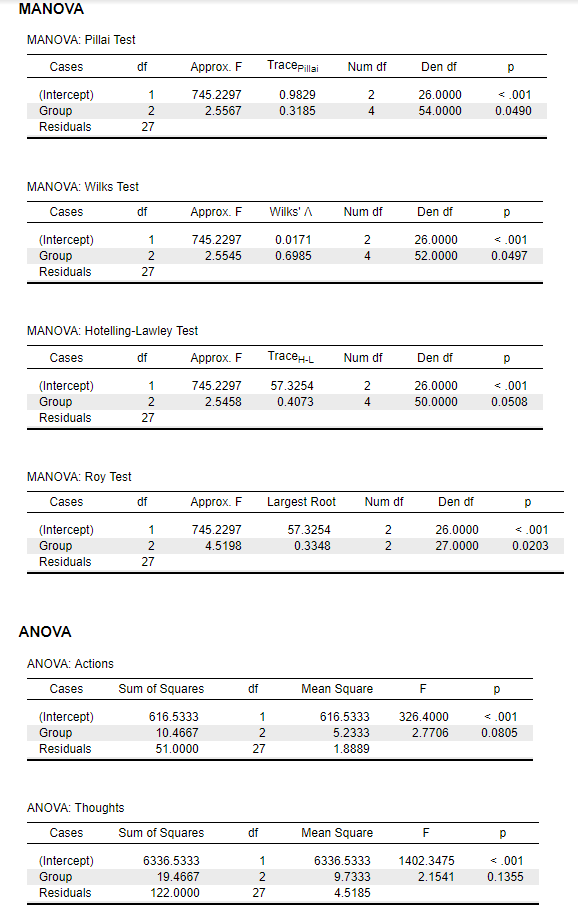
4.7.3 SPSS
DATASET ACTIVATE DataSet2.
GLM Actions Thoughts BY Group
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/CRITERIA=ALPHA(.05)
/DESIGN= Group.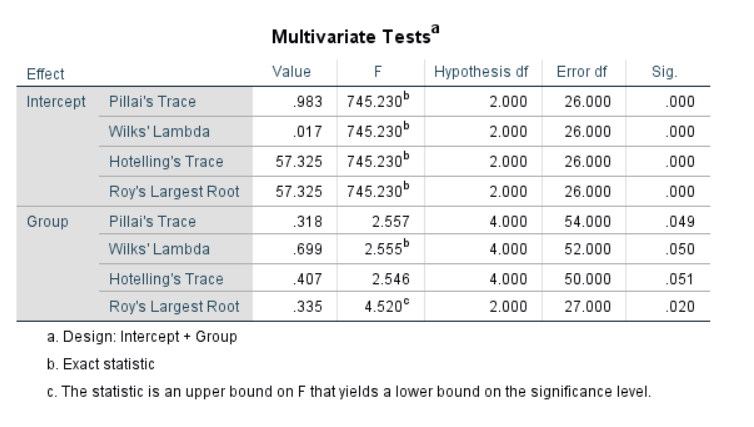
Figure 4.26: SPSS Output for MANOVA
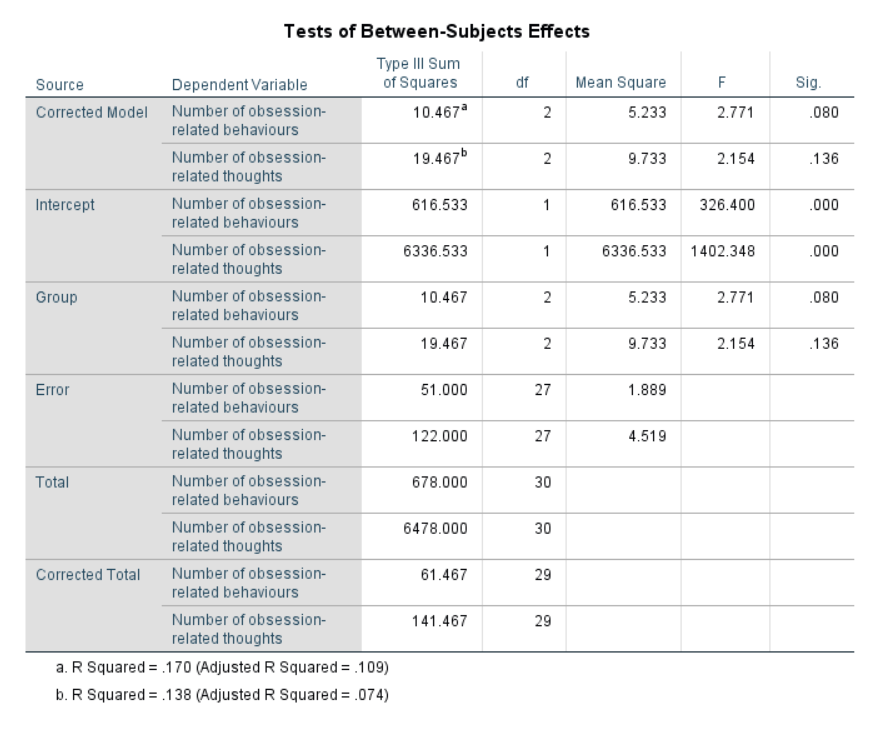
Figure 4.27: SPSS Output for MANOVA
4.7.4 SAS
proc glm data= work.MANOVA plots=none;
class Group;
model Actions Thoughts = group / ss3;
manova h=Group;
run;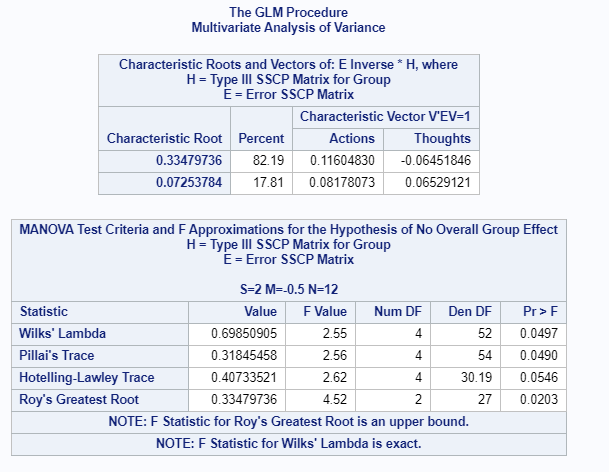
Figure 4.28: SAS Output for MANOVA
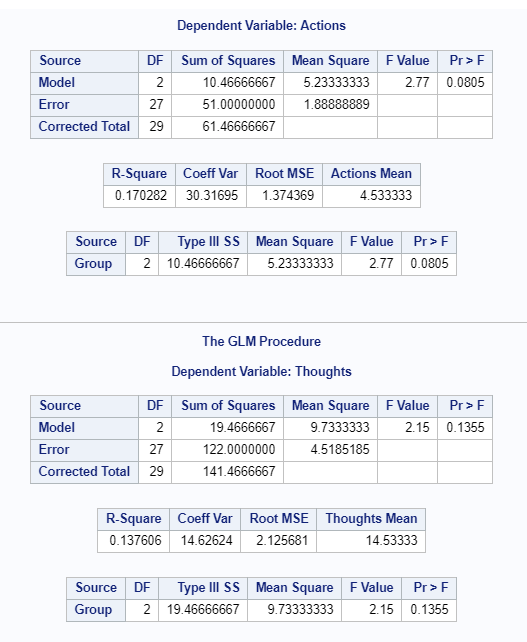
Figure 4.29: SAS Output for MANOVA
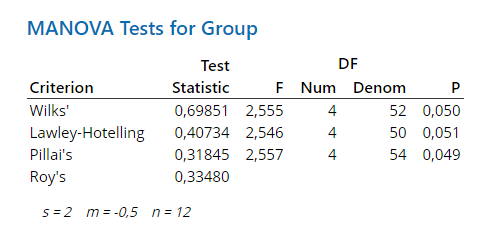
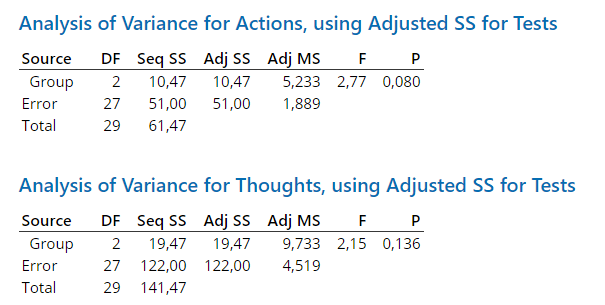
4.7.6 R
DVmanova <- cbind(MANOVA.data$Thoughts, MANOVA.data$Actions)
fit <- manova(DVmanova ~ as.factor(Group), data = MANOVA.data)
summary(fit, test ="Pillai")## Df Pillai approx F num Df den Df Pr(>F)
## as.factor(Group) 2 0.31845 2.5567 4 54 0.04904 *
## Residuals 27
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Wilks approx F num Df den Df Pr(>F)
## as.factor(Group) 2 0.69851 2.5545 4 52 0.04966 *
## Residuals 27
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Hotelling-Lawley approx F num Df den Df Pr(>F)
## as.factor(Group) 2 0.40734 2.5459 4 50 0.0508 .
## Residuals 27
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Roy approx F num Df den Df Pr(>F)
## as.factor(Group) 2 0.3348 4.5198 2 27 0.02027 *
## Residuals 27
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Response 1 :
## Df Sum Sq Mean Sq F value Pr(>F)
## as.factor(Group) 2 19.467 9.7333 2.1541 0.1355
## Residuals 27 122.000 4.5185
##
## Response 2 :
## Df Sum Sq Mean Sq F value Pr(>F)
## as.factor(Group) 2 10.467 5.2333 2.7706 0.08046 .
## Residuals 27 51.000 1.8889
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1